OSS RL environment + evals toolkit. Wrap software as environments, run benchmarks, and train with RL – locally or at scale.



📅 Hop on a call or 📧 founders@hud.so
- 🚀 MCP environment skeleton – any agent can call any environment.
- ⚡️ Live telemetry – inspect every tool call, observation, and reward in real time.
- 🗂️ Public benchmarks – OSWorld-Verified, SheetBench-50, and more.
- 🌱 Reinforcement learning built-in – Verifiers gym pipelines for GRPO on any environment.
- 🌐 Cloud browsers – AnchorBrowser, Steel, BrowserBase integrations for browser automation.
- 🛠️ Hot-reload dev loop –
hud devfor iterating on environments without rebuilds.
We welcome contributors and feature requests – open an issue or hop on a call to discuss improvements!
# Core installation - MCP servers, telemetry, basic tools for environment design
pip install hud-python
# Agent installation - Adds AI providers, datasets
pip install "hud-python[agent]"
# CLI utilities
uv tool install hud-python
# uv tool update-shell
# From source (latest)
git clone https://github.com/hud-evals/hud-python
pip install -e "hud-python[dev]"See docs.hud.so, or add docs to any MCP client:
claude mcp add --transport http docs-hud https://docs.hud.so/mcp
For a tutorial that explains the agent and evaluation design, run (see quickstart docs):
uvx hud-python quickstartOr just write your own agent loop (more examples here).
import asyncio, hud, os
from hud.settings import settings
from hud.clients import MCPClient
from hud.agents import ClaudeAgent
from hud.datasets import Task # See docs: https://docs.hud.so/reference/tasks
async def main() -> None:
with hud.trace("Quick Start 2048"): # All telemetry works for any MCP-based agent (see https://app.hud.so)
task = {
"prompt": "Reach 64 in 2048.",
"mcp_config": {
"hud": {
"url": "https://mcp.hud.so/v3/mcp", # HUD's cloud MCP server (see https://docs.hud.so/core-concepts/architecture)
"headers": {
"Authorization": f"Bearer {settings.api_key}", # Get your key at https://app.hud.so
"Mcp-Image": "hudpython/hud-text-2048:v1.2" # Docker image from https://hub.docker.com/u/hudpython
}
}
},
"evaluate_tool": {"name": "evaluate", "arguments": {"name": "max_number", "arguments": {"target": 64}}},
}
task = Task(**task)
# 1. Define the client explicitly:
client = MCPClient(mcp_config=task.mcp_config)
agent = ClaudeAgent(
mcp_client=client,
model="claude-sonnet-4-20250514", # requires ANTHROPIC_API_KEY
)
result = await agent.run(task)
# 2. Or just:
# result = await ClaudeAgent().run(task)
print(f"Reward: {result.reward}")
await client.shutdown()
asyncio.run(main())The above example let's the agent play 2048 (See replay)

This is a Qwen-2.5-3B agent training a policy on the text-2048 environment (see above) using Verifiers:
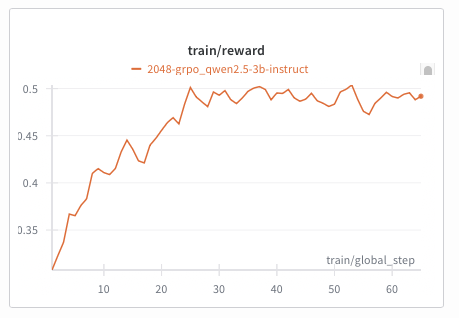
To start training, check out the rl/README.md folder:
git clone https://github.com/hud-evals/hud-python
cd hud-python/rl
python train_2048.pyAny hud MCP environment and evaluation works with our RL pipeline. Even our remote configurations!
The
rl/README.mdwalks you through several examples of RL training and takes less than 15 minutes to set up for your custom agent!
This is Claude Computer Use running on our proprietary financial analyst benchmark SheetBench-50:
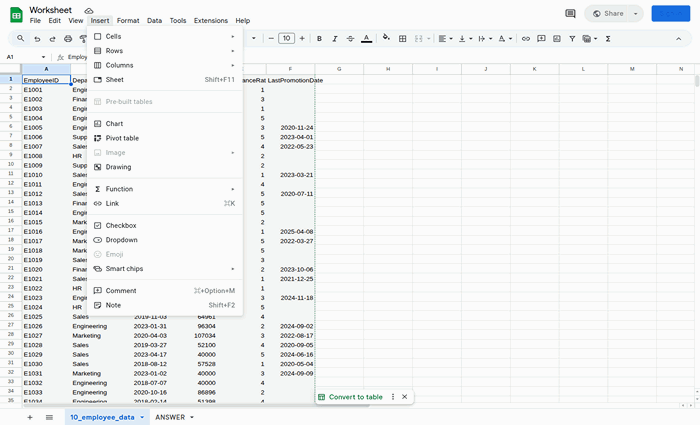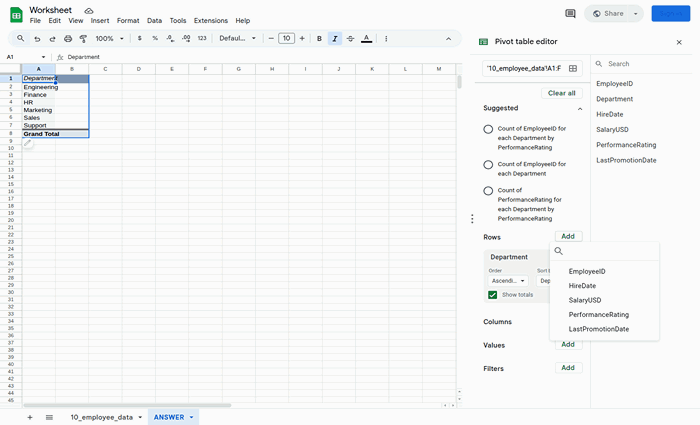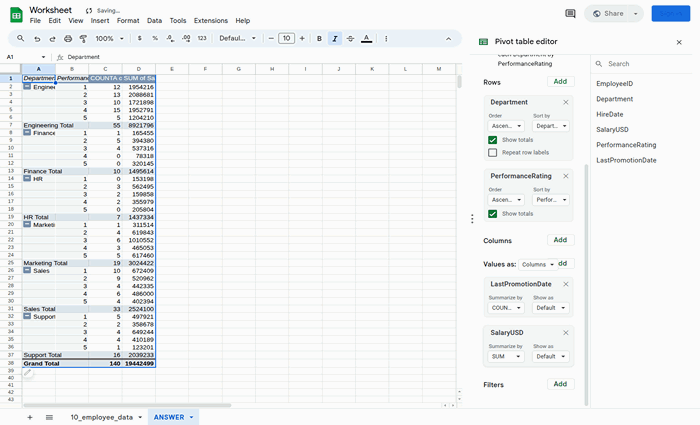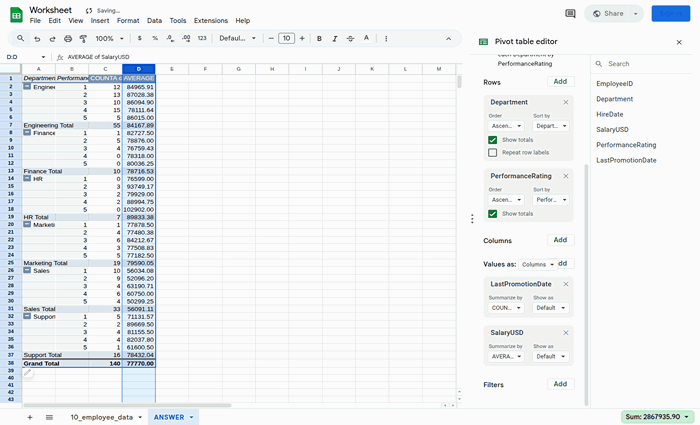
This example runs the full dataset (only takes ~20 minutes) using run_evaluation.py:
python examples/run_evaluation.py hud-evals/SheetBench-50 --full --agent claudeOr in code:
import asyncio
from hud.datasets import run_dataset
from hud.agents import ClaudeAgent
results = await run_dataset(
name="My SheetBench-50 Evaluation",
dataset="hud-evals/SheetBench-50", # <-- HuggingFace dataset
agent_class=ClaudeAgent, # <-- Your custom agent can replace this (see https://docs.hud.so/evaluate-agents/create-agents)
agent_config={"model": "claude-sonnet-4-20250514"},
max_concurrent=50,
max_steps=30,
)
print(f"Average reward: {sum(r.reward for r in results) / len(results):.2f}")Running a dataset creates a job and streams results to the app.hud.so platform for analysis and leaderboard submission.
This is how you can make any environment into an interactable one in 5 steps:
- Define MCP server layer using
MCPServer
from hud.server import MCPServer
from hud.tools import HudComputerTool
mcp = MCPServer("My Environment")
# Add hud tools (see all tools: https://docs.hud.so/reference/tools)
mcp.add_tool(HudComputerTool())
# Or custom tools (see https://docs.hud.so/build-environments/adapting-software)
@mcp.tool("launch_app"):
def launch_app(name: str = "Gmail")
...
if __name__ == "__main__":
mcp.run()- Write a simple Dockerfile that installs packages and runs:
CMD ["python", "-m", "hud_controller.server"]And build the image:
hud build # runs docker build under the hoodOr run it in interactible mode
hud dev- Debug it with the CLI to see if it launches:
$ hud debug my-name/my-environment:latest
✓ Phase 1: Docker image exists
✓ Phase 2: MCP server responds to initialize
✓ Phase 3: Tools are discoverable
✓ Phase 4: Basic tool execution works
✓ Phase 5: Parallel performance is good
Progress: [█████████████████████] 5/5 phases (100%)
✅ All phases completed successfully!Analyze it to see if all tools appear:
$ hud analyze hudpython/hud-remote-browser:latest
⠏ ✓ Analysis complete
...
Tools
├── Regular Tools
│ ├── computer
│ │ └── Control computer with mouse, keyboard, and screenshots
...
└── Hub Tools
├── setup
│ ├── navigate_to_url
│ ├── set_cookies
│ ├── ...
└── evaluate
├── url_match
├── page_contains
├── cookie_exists
├── ...
📡 Telemetry Data
Live URL https://live.anchorbrowser.io?sessionId=abc123def456- When the tests pass, push it up to the docker registry:
hud push # needs docker login, hud api key- Now you can use
mcp.hud.soto launch 100s of instances of this environment in parallel with any agent, and see everything live on app.hud.so:
from hud.agents import ClaudeAgent
result = await ClaudeAgent().run({ # See all agents: https://docs.hud.so/reference/agents
"prompt": "Please explore this environment",
"mcp_config": {
"my-environment": {
"url": "https://mcp.hud.so/v3/mcp",
"headers": {
"Authorization": f"Bearer {os.getenv('HUD_API_KEY')}",
"Mcp-Image": "my-name/my-environment:latest"
}
}
# "my-environment": { # or use hud run which wraps local and remote running
# "cmd": "hud",
# "args": [
# "run",
# "my-name/my-environment:latest",
# ]
# }
}
})See the full environment design guide and common pitfalls in
environments/README.md
All leaderboards are publicly available on app.hud.so/leaderboards (see docs)
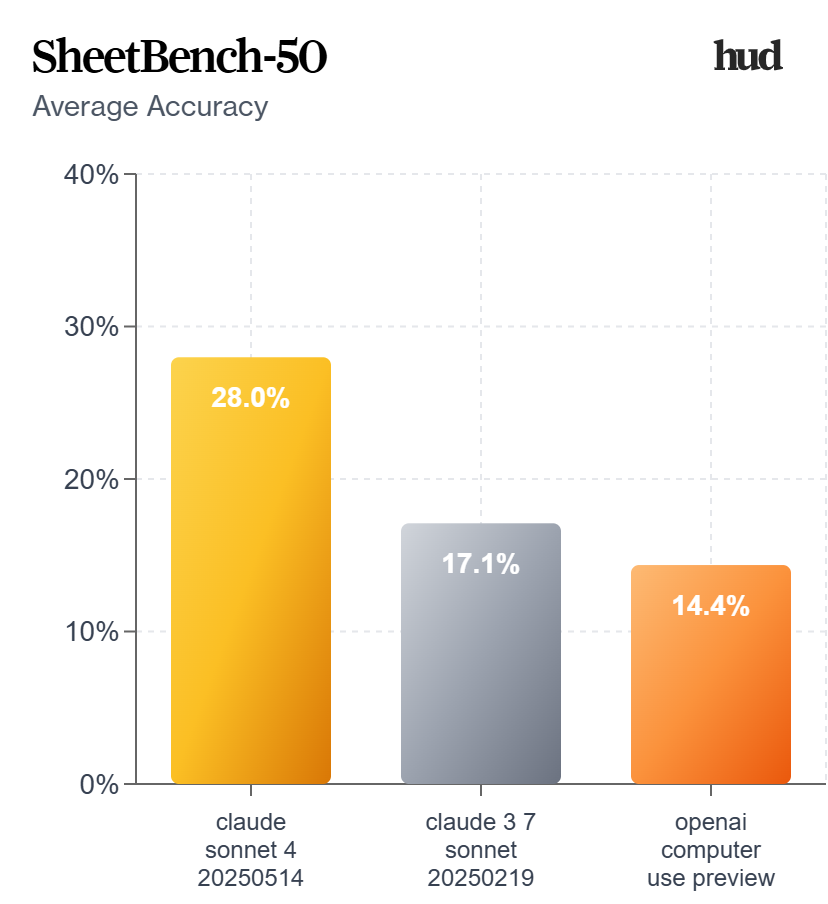
We highly suggest running 3-5 evaluations per dataset for the most consistent results across multiple jobs.
Using the run_dataset function with a HuggingFace dataset automatically assigns your job to that leaderboard page, and allows you to create a scorecard out of it:
%%{init: {"theme": "neutral", "themeVariables": {"fontSize": "14px"}} }%%
graph LR
subgraph "Platform"
Dashboard["📊 app.hud.so"]
API["🔌 mcp.hud.so"]
end
subgraph "hud"
Agent["🤖 Agent"]
Task["📋 Task"]
SDK["📦 SDK"]
end
subgraph "Environments"
LocalEnv["🖥️ Local Docker<br/>(Development)"]
RemoteEnv["☁️ Remote Docker<br/>(100s Parallel)"]
end
subgraph "otel"
Trace["📡 Traces & Metrics"]
end
Dataset["📚 Dataset<br/>(HuggingFace)"]
AnyMCP["🔗 Any MCP Client<br/>(Cursor, Claude, Custom)"]
Agent <--> SDK
Task --> SDK
Dataset <-.-> Task
SDK <-->|"MCP"| LocalEnv
SDK <-->|"MCP"| API
API <-->|"MCP"| RemoteEnv
SDK --> Trace
Trace --> Dashboard
AnyMCP -->|"MCP"| API
| Command | Purpose | Docs |
|---|---|---|
hud init |
Create new environment with boilerplate. | 📖 |
hud dev |
Hot-reload development with Docker. | 📖 |
hud build |
Build image and generate lock file. | 📖 |
hud push |
Share environment to registry. | 📖 |
hud pull <target> |
Get environment from registry. | 📖 |
hud analyze <image> |
Discover tools, resources, and metadata. | 📖 |
hud debug <image> |
Five-phase health check of an environment. | 📖 |
hud run <image> |
Run MCP server locally or remotely. | 📖 |
- Merging our forks in to the main
mcp,mcp_use,verifiersrepositories - Helpers for building new environments (see current guide)
- Integrations with every major agent framework
- Evaluation environment registry
- Native RL training to hud environments (see current RL support)
- MCP opentelemetry standard
We welcome contributions! See CONTRIBUTING.md for guidelines.
Key areas:
- Environment examples - Add new MCP environments
- Agent implementations - Add support for new LLM providers
- Tool library - Extend the built-in tool collection
- RL training - Improve reinforcement learning pipelines
Thanks to all our contributors!
@software{hud2025agentevalplatform,
author = {HUD and Jay Ram and Lorenss Martinsons and Parth Patel and Oskars Putans and Govind Pimpale and Mayank Singamreddy and Nguyen Nhat Minh},
title = {HUD: An Evaluation Platform for Agents},
date = {2025-04},
url = {https://github.com/hud-evals/hud-python},
langid = {en}
}License: HUD is released under the MIT License – see the LICENSE file for details.